DID stands for Decentralized IDentifier, Decentralized Identity Document, and Decentralized IDentity all at the same time. Got it? Good. Now don’t use the word DID, don’t use the DID technology, and most of all don’t use the W3C DID standards. With user sovereignty as its guide and ethics as its foundation, the authentic data economy solves the problems plaguing DIDs, DIDs, and DIDs.
Don’t Use DIDs
The W3C has been hard at work for the last four years in endless political fights over the design of the standard for decentralized identity documents and their identifiers. The end result is a design-by-committee solution that is malformed, didactic and fights adoption. It fails to meet basic requirements for a global, decentralized digital trust and identity system and it abandons the principles of user sovereignty and the ethics those bring. It is also heavily tailored for the web when decentralized identity is an Internet — and not just web — technology. Trying to make it web friendly creates clunky designs based on “canonicalization protocols” and other details that get lost in implementations and ultimately hurt interoperability. The worst part is that limitations in the cryptography have led companies to create solutions that do not support privacy preserving own-your-own-data systems which was the whole point of self-sovereign identity in the first place.
There are three major flaws that effectively make the W3C standards completely unusable as a universal solution. As I describe them you will see a repeating pattern that highlights how half-baked the standards really are.
Problems with DIDs
The W3C standard for DIDs — sorry, Decentralized IDentifiers — conflates identification with location causing complete chaos in the implementation and adoption of the standard in a portable and interoperable way. The standard states, “DIDs are URIs that associate a DID subject with a DID document allowing trustable [sic] interactions associated with that subject.” The implication is that a DID (identifier) both names and locates a DID (document).
By creating a standard URI format that both identifies and locates, the result is a ridiculous explosion of pet storage and provenance solutions, each one having their own decentralized identity “method” standard that specifies how applications are to interact with the DIDs (documents) they manage. The registry of DID methods contains 94(!!) different methods at the time of this writing. A fully compliant application would have to support all of them which, in most cases, requires access to a running full node on whatever blockchain platform the DID method is linked to.
This is wrong in a lot of ways but most importantly it harms:
- Scalability
- Interoperability
- Portability
Three of the most important capabilities of software systems that claim to embody the principles of user sovereignty.
Problems with DIDs
The W3C standard for DIDs — sorry, Decentralized Identity Documents — doesn’t meet the basic requirements for an Internet-scale provenance-driven digital identity solution. DIDs (documents) completely ignore the dimension of time. To put it more precisely, they provide no solution for tracking the evolution of digital identities and their associated data (e.g. cryptographic keys) over time. There is no mechanism for recording key rotations and other provenance aggregations that occur over the lifetime of the controller.
It is a good habit to rotate cryptographic keys on a regular basis even if they have not become compromised. The consequence of having old keys is that there is, and always will be, old data that is digitally signed by those old keys. In the authentic data economy nearly all data will have some form of digital signature ensuring its integrity. The Internet never forgets any data and old, digitally signed data will require old keys to verify the signatures.
DIDs (documents) do not support this. Some DID methods such as Microsoft’s ION do keep a history of the changes made to a DID (document) but the history is not available in the “rendered” DID (document) retrieved from their storage solution. This makes it extremely difficult for old data to be verified using the old keys. The W3C DID method standard only specifies basic read, write, update, and delete operations with no standard method for accessing the history of a DID (document). In the end, any tool used for validating signatures will have to be programmed to work with each of the 94 different DID methods and their peculiar way to access history to get old keys.
This is wrong in a lot of ways but most importantly it harms:
- Scalability
- Interoperability
- Portability
Three of the most important capabilities of software systems that claim to embody the principles of user sovereignty. The repetition is intentional; the pattern of mistakes is real.
Problems with DIDs
The W3C standard for DIDs — sorry, Decentralized IDdentities—suffers from a major lack of replaceable DID methods and services. Standards are supposed to specify common protocols and common formats so that any piece of software can be written that adheres to the standard and it can be replaced by another piece of software that adheres to the same standard. Replaceability is critical in empowering the users of the system. Anything that makes users beholden to a particular software implementation is, by definition, a vendor-locked silo. Because not all DID methods and their associated DIDs (identifiers) and history mechanism for DIDs (documents) are the same, moving from one method/implementation to another is neither automatic nor universal.
Truly decentralized and user sovereign systems use open, standard file formats and open, standard protocols to ensure that users are free to take their data from one system to another with minimal effort. The best example we have today is still good ol’ fashioned email. Anybody can use an IMAP protocol client to download all of their email from their email provider (e.g. GMail, FastMail, SDF.org), store the messages on their computer in the open, standard mbox files and then later use the IMAP client to upload them to a different email provider. This is only possible because email servers and clients all adhere to a set of standards that leave no room for implementation-specific peculiarities that lead to vendor-locked users and siloed data.
TL;DR: A Better Way
I’m not the kind of person to light something on fire and walk away. I don’t complain unless I have a solution to offer. But be warned, the rest of this article is fairly technical and aimed directly at the existing DID community of developers and technologists. There is a better way to achieve the goals of the DID (identity) standards while preserving interoperability, portability, and most of all, enabling scalability. Inspired by all of the tremendous work and effort already put into the DID community and standard, the authentic data economy uses a new set of standards that solve all of the issues outlined above while also achieving scalability that is at least eight magnitudes (i.e. 10⁸) larger than the most DID based solutions today. Right now the largest DID systems are dealing with a few million pieces of authentic data created by a few dozen “issuers” but what I am about to propose is capable of supporting billions of “issuers” creating billions of pieces of authentic data that get verified by billions of verifiers. It is so scalable that anybody and anything can create authentic data that has an associated provenance log that tracks the history of the data, data that can be identity data (e.g. key pairs), universal non-token based NFTs (i.e. unique data with provable ownership), or any other kind of data that benefits from added trust.
Before I get to the details, I want to point out one other primary difference between the DID system approach and the authentic data approach. Up until now it has been assumed that DID systems have “permissioned” issuers/creators of authentic data. The further assumption is that some governance framework binds issuers to a set of legal rules/regulations and there are a few, well-known issuers. Just look at the Trust-over-IP Foundation’s “dual stack” approach; it has a governance stack that is on par with the technology stack. This approach is very didactic and top down; it is hierarchical and corporate. User sovereignty demands a bottom up, user-centered approach that empowers users to own their data and to use cryptography to protect their privacy. Issuers in the authentic data economy are unpermissioned and as plentiful as people and devices.
Governance frameworks are like Newton’s laws of motion, they are nice to have when understanding the nature of a system, however — just like gravity — cryptography works with or without written rules.
The provenance log based approach to the authentic data economy is designed specifically to maximize user sovereignty and needs no permission to work. The trust doesn’t come from rigid governance but rather it comes from providing an independently verifiable way for existing trusted entities — be they organizations, governments, individuals, or computers or even a single application process — to create data that is independently verifiable to have come from where it says it came from, was sent to where it says it is destined to go, and that it has not been modified since creation.
Revocation, Privacy and the Four-Party Model
One last piece of information before I summarize provenance logs. I want to talk about revocation. Revocation is a key feature that everybody must be aware of. In your mind, when you hear “revocation” I want you to think “privacy” because it is critical to the preservation of our digital privacy. I know I’m not the only one who thinks this way. Recently Adreas Freitag conducted a survey of technologists in the DID community asking about revocation and the results show that 61% of respondents think privacy is the primary concern with revocation. In the authentic data economy we will be issued authentic personal data from trustworthy sources (e.g. doctor, banker, insurer, credit rating agency, etc) that we will use to interact with the world. The authentic personal data is the underlying data upon which zero-knowledge proofs are created. Zero-knowledge proofs (ZKPs) are how we prove things to others about our authentic data without revealing the authentic data itself.
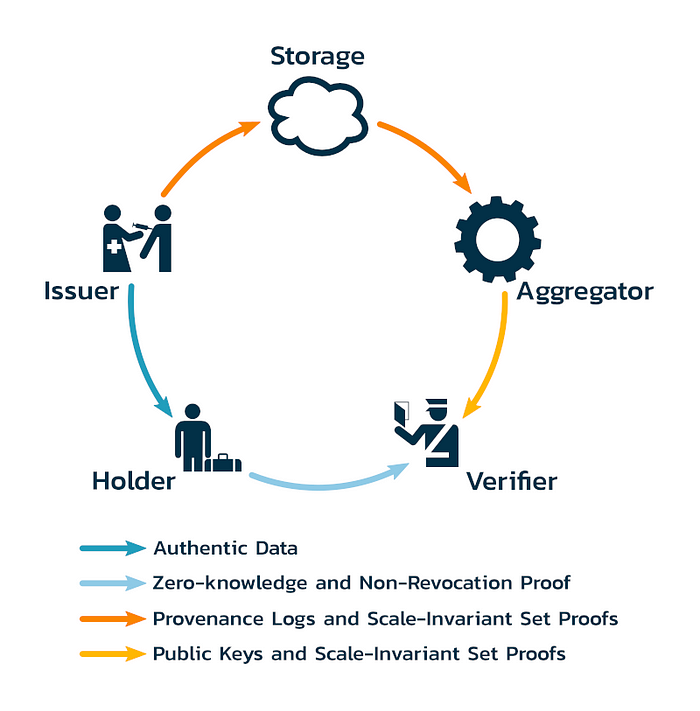
However, there is a trust issue that ZKPs suffer from that is similar to one that X.509 (HTTPS) certificates suffer from that is solved by checking the validity of the underlying data/certificate when it used. In the X.509 world of HTTPS web servers, the validity checks are done using the Online Certificate Status Protocol. In the authentic data economy, there is a four-party model instead of the three-party model used with DIDs (identities). Authentic data issuers of publish non-revocation set proofs in their provenance logs and those proofs are gathered by aggregators and pushed to verifiers. The set proofs allow for holders of authentic data to include a proof that their underlying data is in the set of valid authentic data and that it hasn’t been revoked by the issuer. By including a non-revocation proof with the associated ZKPs, verifiers can be certain that the underlying data is still valid according to the issuers.
The aggregator mentioned above plays a critical role that solves the many-to-many problem between issuers and verifiers. The online certificate status protocol has some concerns over privacy given that whenever the certificate is used a check with the issuer happens. This is a form of correlation and reduces the privacy of the holder of the authentic data. By including an aggregator, all of the set proofs and issuer key data is pushed to verifiers when it is published by the issuers. This allows for the same kind of “late binding trust” that OCSP offers but without the reduction in privacy and it also creates the ability to do offline transactions. Let that sink in for a second. Aggregators pushing non-revocation set proofs and issuer public keys to verifiers means that holders and verifiers can transact in a trustful way even with both of them are completely disconnected and offline.
The Authentic Data Stack
TrustFrame is attending the Internet Identity Workshop (IIW) on April 20th–22nd, 2021 where we plan to launch a new open source stack that makes the authentic data economy possible. We have already begun publishing documentation about critical pieces of the infrastructure. To fix the DID — no, DID — I mean, DID — problems I described above, we have proposed open standards for authentic data provenance logs, authentic data names, and authentic data locators. Be warned, they proposals are fresh and definitely under construction. They document the existing working code that will be open sourced as part of our presentation at IIW. We welcome anybody who wants to contribute as we refine things.
First of all authentic data provenance logs are used to create a time-oriented log of identity data such as cryptographic key pairs, registrars used for proof-of-existence, and any associated authentic data. They are designed to be compact and binary to simplify digitally signing and verifying the data within them.
Second, authentic data identifiers are a proposed URN (e.g. urn:adi:…) standard for self-certifying identifiers calculated directly from the authentic data provenance logs. They are made up of several parts, the first part is the cryptographic digest of the first, inception event of the log which creates a name that is globally unique and persistent for the life of the provenance log. The last parts of the identifier contain the cryptographic digest of the most recent event in the provenance log. This head-to-tail self-certifying identifier scheme gives end-to-end integrity guarantees and is used to defend against truncation attacks and to prove that a copy of a provenance log is complete.
The authentic data identifier must be “anchored” with a registrar every time an event is added to the provenance log — including the first event. We will be open sourcing a registrar service that supports recording accumulator values in Bitcoin nulldata transactions for the proof-of-existence. The registrar uses an RSA based cryptographic accumulators to accumulate hashes of identifiers that are used to prove that a given provenance log existed and what its state was at a given point in time. By open sourcing the registrar, anybody can stand one up and run it. The more the better because choice in registrars further enhances the privacy and user sovereignty of provenance log controllers. Portability across registrars is enforced by the open standards and data formats. The design and game theory only requires one honest registrar for the authentic data economy to work. Maybe there is a future where Mozilla and/or the EFF runs a free, public, and honest registrar to ensure open and free access to the Web and Internet respectively. We chose Bitcoin because we like it but the registrar can use any back-end storage. The only requirements are that the storage spans the trust domains in which the authentic data must be trusted and it is available to all participants in the trust domain. If the authentic data only has to be trusted within a single organization, the registrar can use a simple SQL database. If the authentic data is a “universal” NFT that isn’t tied to a cryptocurrency token, the registrars must use a public blockchain such as Bitcoin so that the proof-of-existence is available globally.
Third, authentic data locators are created using a proposed protocol for calculating resolvable URLs to authentic data logs from the authentic data identifier URNs and cryptographically binding them by including a compact BLS signature in, and over, the locator. By separating the identifiers from the locators, controllers of provenance logs are free to store their provenance logs in multiple locations of their choosing and use multiple locators. By using the locator to retrieve the provenance log, the BLS signature over the locator can be validated using the public key in the log. Users are now in charge with the provenance log cryptographically decoupled from the storage which prevents siloing. Any storage — trusted or not — works just fine. Throw it on your web server, chuck it into an S3 bucket, put the log into a data URL and print it on paper as a QR code. It doesn’t matter, the URL is cryptographically linked to the URN which is in turn cryptographically linked to the provenance log which can be proven to be complete and to have existed using proofs issued and anchored by a registrar.
This new set of proposals and open source code solves all of the problems with DIDs, DIDs, and DIDs that I outlined in this article. It fixes the old keys problem. It eliminates the DID method registry with its 94 corporate-backed silos for storing everybody’s data. It streamlines all aspects of establishing and maintaining provenance so much that there is no reason why all data can’t be authentic data.
If architecture and standardization decisions [are] made “wrong”, we end up with just another federated identity.
User Sovereignty is our Guide, Ethics is our Foundation
The six principles of user sovereignty are:
- Absolute privacy by default
- Absolute pseudonymity by default
- Strong, open encryption always
- Standard, open protocols and data formats for all data
- What, not who, for authorization
- Revocable consent-based power structure
As we digitize trust at a global scale, we have to be very careful that we do not build systems that circumvent established ethics and principles that protect the powerless and the individual. What that means is if the authentic data economy is to handle medical data, the application must be built according to ethics that align closely with the ethics of the medical practice. If the authentic data economy is to handle private legal data, the application must be built according to ethics that align closely with the ethics of the legal practice. This is true for all data, in all applications. The authentic data economy is about digitizing human scale trust. It really is about putting our social fabric onto computers in a way that enhances the human condition instead of destroying it.
The TrustFrame proposal and implementation was designed to strictly adhere to the principles of user sovereignty. Whenever there were multiple solutions we always chose the solution that followed the principles. In our solution the first three principles are self-evident. Provenance logs and the infrastructure supporting ZKP presentation by default supports absolute privacy, absolute pseudonymity and the implementation uses strong, open cryptography.
The fourth principle is supported by us publishing the documentation as a proposed standard that is properly licensed and ready for the standardization process at the IETF. The authentic data proposals are for an Internet standard that solves an Internet problem. It will also be useful in the Web context but the primary focus is not the Web.
The fifth principle is true simply because all authorization is done with the use of cryptographically signed proofs that act like bearer tokens for authorization. If you control the logs, you can authorize. The sixth principle is handled by the use of provenance logs for everything. Interaction between any two controllers requires each to have a key pair for the interaction, managed by their respective provenance logs. If the logs record every message that passes between the controllers, any consent requested and granted is recorded in both logs. Revocation of consent is through unilateral key rotation by the consenting controller.
One Last Thing…
I recently bought an image NFT on OpenSea. I paid roughly $20 in WETH for it and the mining fee to transfer it was $46!! To further prove my point about the authentic data economy I decided to liberate the NFT from the OpenSea silo so that I will never have to pay a $46 mining fee for a $20 piece of data. I created a provenance log containing a BLS public key and meta data about the image. I calculated the identifier URN from the log and anchored it into my registrar which recorded it into the Bitcoin blockchain. I then took the first part of the identifier — the hash of the first event — and I sent the NFT ethereum token to an address that was equal to the identifier, burning the token, making it nontransferable and forever crypographically linking the NFT to the provenance log. I now own the world’s first universal and independently managed NFT. Since it is no longer tied to a “token” for tracking ownership, can we call it non-fungible authentic data (NFAD)?
I just worked out a variant of the PayPub protocol to enable a cross-chain swap of the NFAD to a new owner in exchange for Bitcoins. Come to IIW and see how I did it. I may even sell my NFAD to someone.