
All of us intuitively have a sense of what trust is and how to earn and maintain it as well as how to lose it. Trust never comes for free. The cost of earning trust is consistent trustworthy behavior over time. It forms our reputation in our social circles. But what happens when you have to do business outside of our personal social circles, such as with a new bank, or with a government agency far removed? How is trust established then? How is it transmitted to the distant institution to conduct business and how is it transmitted back? Over human history the solution has been to generate and keep official records about people and their activities. Some examples of official records are: Jane was born on this date, John earned his diploma from this university in this year, Judy received a license to practice medicine.
What makes some records official and why do we trust them? Usually it is because they come with a guarantee of authenticity from a social, cultural, governmental, or corporate institution which has earned broad trust from society at large. The characteristics of these official records — the things that make them official — are largely the same. We know where the records came from (e.g. government issued), we know to whom they were given (e.g. the person pictured on the ID), and we know that the data in the record has not been changed (e.g. tamper proofing is intact). Official records, or more broadly, “authentic data” has underpinned humanity’s trust network since the dawn of civilization. The image at the top of the article is a Sumerian harvest record created by an official around 3,100 B.C. It is an example of the earliest known human writing using an alphabet. It is also authentic data that was intended for use in official decision making.
The development of human literacy, interestingly enough, may have been a response to the environmental pressures that came with civilization. It is clear that we started off as nomadic peoples and that learning to speak was probably the most effective way to coordinate hunting and other survival activities. But then when we grouped together into cities maybe learning to write was the most effective way to coordinate civilization? It kind of makes you wonder.
Now, fast forward to the present and not much has changed. As a society we still make and keep authentic data records that are used to judge and mitigate the risk in any business dealings. This use of authentic data is critical whenever business transactions happen between parties that are not familiar with each other. Whenever the process of establishing trust must be expedited — such as in legal agreements or financial transactions— we have societal systems in place whereby untrustworthy actions come with legal, monetary and/or criminal penalty. The cost of untrustworthy behavior is intended to incentivize trustworthy behavior and allow for the trustful interaction to proceed and the associated authentic data is used directly for enforcement and penalty.
To this day — even with mass computerization — trust-based interactions stubbornly resist digitization and remain at human scale simply because of the way we keep and maintain authentic data records. Tasks such as opening a bank account, having a document notarized, or signing a contract typically involves an in-person meeting to present the authentic data records (e.g. government identification, proof of funds, etc) and to sign a “wet” signature. However, now that we live in a reality twisted by the DNA strands of the COVID-19 virus, how do we ever hope to get back to in-person business as usual and trust as usual? Even if we can vaccinate against the virus and restore normal human interaction, the need for a more lasting technological solution for establishing trust remotely and transmitting it over great distances still exists. This, I believe, is the last great problem in technology and solving it will create the next crop of billion-dollar companies and billionaire founders.
A Brief History of Technological Innovation
For the last eight decades, we have experienced wave after wave of computerization focused on taking human-scale functions of society and shrinking them down to the scale of the microchip, through digitization, to increase efficiency by magnitudes. Born out of WWII, digital computers quickly found use in business with applications focused on digitized data gathering (i.e. data entry terminals) and record keeping (i.e. mainframe databases).
By the late 1960’s, companies such as IBM, Hewlett-Packard, and DEC grew to massive proportions designing and building mainframe computers for business. In the late 1970’s, during the dawn of the personal computer (PC) era, we saw digitized business practices such as accounting (i.e. spreadsheets) and communicating (i.e. word processing, email). Again, we saw a new crop of companies such as Digital Research, Microsoft, and Apple eclipse the previous computing giants. At the same time, the first class of famous nerds emerged: Gary Kildall, Bill Gates, Steve Jobs and Steve Wozniak respectively. In the 1990’s the web digitized publishing and e-commerce and another wave of companies eclipsed the previous generation. Amazon, AOL, Geocities, eBay, and PayPal seemed to come out of nowhere; some have lasted, some have not. In the 2000’s, computerization brought about the digitization of broadcasting (i.e. YouTube), our social circles (i.e. Facebook), general human knowledge (i.e. Wikipedia) and even operational decision making with artificial intelligence (i.e. Google, IBM, and others).
As you can see, over the last 80 years there were roughly four eras: mainframe (1940–1970), PC (1970–1990), web (1990–2007), and social (2007–preset) that lasted roughly 30, 20, 17, and 13 years respectively. Not only is the pace of innovation accelerating but with each successive wave the innovation is focused on digitizing more parts of human society. It has been roughly 13 years since the social era of technology began and the stage is set for the next wave to start; but what else is left to digitize? Computerizing trust appears to be all that remains. The solution is overdue mostly because its scope is so large it encompasses all previous digitization and computer innovation. It appears that digitized trust can’t come soon enough. With greater access to digital systems world wide, fraud of all kinds is on the rise everywhere: identity theft, benefits fraud, and payments fraud are the most widespread. Without a secure and global means of creating, transmitting, and verifying authentic data, we risk the breakdown of digital systems under the weight of over-regulation, increased risk monetization, and general mistrust by the people that use them. The big question is how do we achieve digitizing trust without risk to our human rights and without isolating large portions of the global population that still have limited access to technology?
Information Theory and Trust
Let us take a short tangent and talk about bandwidth. Bandwidth is the term used to describe how much data can be transmitted over a wire or radio waves; the rate at which data moves from one place to another. Narrow bandwidth means very little data, like a trickle of water out of a garden hose, and wide bandwidth means just the opposite, like a fire hose. It is important to realize that the Internet — even with all of its globe spanning fiber optic cables and massive bandwidth capacity — has relatively narrow bandwidth compared to information exchanged during a face-to-face meeting. The Internet doesn’t reliably transmit facial expressions, voice intonation, eye contact patterns, or any of the countless other social queues we all use to judge the character of people who are unfamiliar to us. Nor does the Internet aid in observing a person’s behavior and judge its consistency over time. Things are improving with video conferencing but no video conference is as good as an in-person meeting, especially when you’re trying to size somebody up. An important ingredient in digitizing trust is figuring out a solution to compress the amount of information we expect to get when forming a trusted relationship.
Another important aspect to digital trust is the authenticity of the information we receive about other people. Social media platforms such as Twitter and Facebook make it easy to spot the loudmouth imbeciles among us but that doesn’t help when we need to be certain of someones’ identity and trustworthiness before signing a contract. We need something else, something that makes it possible for people to receive, hold, and then pass along authentic data that can be trusted.
Authentic data can be any data relevant to a digital or real-world interaction. Authentic data always has a source, a destination, and some tamper resistance. Authentic data must be independently verifiable as having come from its purported source, sent to its stated destination and not modified in any way. It can be proof of someones’ real-world identity or it can be records about their behavior (e.g. credit history); all that matters is that the data is relevant to the interaction and that it is authentic. That’s it! That’s all we need to digitize trust. Simple right? In theory, yes, but in practice there is a lot that needs to be put into place to make it happen. We need a framework and some infrastructure that facilitates the creation, transmission, and verification of authentic data. We also need the digital trust system to follow all financial regulations, privacy regulations, healthcare data regulations, government identification regulations, consumer protection laws, digital signature laws, and ethical norms, all while fitting nicely into our mobile-centric digital lives. On a techno-morality level, the system must also be fully user-sovereign and decentralized in order to avoid becoming the primary tool for violating human rights through gating access to our basic needs such as food, shelter, work and travel. A centralized, government or corporate run version of authentic data based digital credentialing is just a population controlling social credit system by another name.
Up until now, you — the reader — have slowly climbed up the learning curve from the introduction, through computing history all the way to the problem statement of digital trust; like the clack-clackity first hill of a roller coaster. You’re now at the top and from here on the information comes faster and is more complex. I have done my best to provide supporting links for technical terms and concepts but like all endeavors into new territory some degree of courage to press on is required. You may not understand every word or every concept but it doesn’t matter — and you shouldn’t worry — I intend for this article to be the first time most people read about the authentic data economy (ADE). Hang on, here we go.
Rubber, Meet Road
So, how do we prove the source, destination, and integrity of authentic data? The best technology for this is cryptography. Cryptography relies on mathematical problems that are so complex, with numbers so large, they can only be solved by machines that possess the correct and/or secret data to reveal the answer. One application of cryptography can be leveraged to create what are called “cryptographic proofs” about data. There exists today cryptographic proofs that can prove that data was created by someone, was sent to a specific person, and that it hasn’t changed. As stated above, that is all we need to create an authentic data system and a broader trust-based economy based on it.
To be able to create these proofs people need to have their own cryptographic keys and the ability to digitally sign any data — proving that it came from them. Digital signatures also prove that data has not changed since it was signed, otherwise the signature is no longer valid when verified. There are two ways to prove the recipient. First, include the public part of the recipient’s cryptographic keys in the authentic data that is digitally signed. The second is by encrypting the data so that only the recipient can decrypt and read it. Software capable of doing this has existed for decades but, as you will soon see, there are a myriad of reasons why global adoption was not possible until today.
To better illustrate the concept with a real-world example, let us examine an existing system that operates using authentic data to transmit trust. The most widely used authentic data system is the Certificate Authority (CA) system. The what? The Certificate Authority system is known by most people as the “little lock” 🔒 in your web browser’s address bar. The gist of how the CA system works is this: Certificate Authorities are companies that do “extended verification” of legal entities, such as corporations, and then they issue what is called an X.509 certificate to the corporation that contains the data the CA verified (e.g. company name, domain name, etc) as well as an encryption key pair the corporation can use to digitally sign data. The X.509 certificate is itself a piece of authentic data; it is an identity proof backed by the regulated Certificate Authority and links a cryptographic key pair with an identity.

What do corporations use X.509 certificates for? They put them on their web servers and they use the encryption keys to send encrypted data to the web browser proving that the web server is owned and run by the corporation and that the web page sent to the browser is authentic data. The little lock you see in your browser’s address bar signals that all of this has taken place. Clicking on the lock reveals the name of the corporation that sent the authentic data and describes the guarantee that the data your browser received was encrypted and authentic. If you have a sharp eye, you may have noticed in the image above that the data in the certificate was verified by DigiCert Inc. DigiCert is the certificate authority that verified the data and issued the certificate to A Medium Corporation, the publisher of the web site you are currently reading.
If the CA system works so well, why don’t we use it for all data and all trustful interactions on the Internet? The main reason is due to the structure of the CA system. The CA system is client-server but the broader human society and economy is inherently peer-to-peer. In specific terms, the CA system is unidirectional and top-down. The authentic data only flows in one direction: from the web server to the web browser, and the authenticity of the participants flows from the CA to the corporation to the reader. Humans don’t normally work like that. We usually have information and data flowing in both directions when we interact with others. What is needed to truly unlock the full potential of the ADE is a decentralized and open system for:
- establishing and asserting control over cryptographic keys and the digital identities linked to them
- infrastructure for supporting the creation — or issuance — of authentic data
- infrastructure for supporting the verification of authentic data
It seems rather straightforward but as I said in the beginning, this is one of the last hard problems of computerization.
Digital Identity
Participating in the ADE starts with establishing a digital identity. Even though we use the word “identity” the meaning in this case is fundamentally different what you may think of in the real-world. Digital identities are just encryption keys — so called public-private key pairs (“key pairs” or “keys”)— that are controlled by somebody or something (i.e. the “controller”). By using these keys to digitally sign data, the controller of the keys — the owner of the identity— can ultimately demonstrate consistent behavior over time in a digital way through a process called correlation.
Here is an example of correlation in action. If the controller of an identity is a wizard at picking the winners of football games and they digitally sign and publish their picks each week, they can develop a reputation as being good at picking winners. Nobody can steal their identity or impersonate them because only the controller can digitally sign and publish data using the keys they possess.
If the controller goes on to publish data about horse race predictions and they digitally sign those with the same keys, people can independently verify that the data came from the football picking wizard and can make a value judgement based on the controller’s reputation as a winning sports picker.
The important takeaway is that by using cryptography and control over cryptographic key pairs, a controller can assert their identity on the Internet. This is the first and most fundamental piece of the ADE. Once established, controllers use their identities in all online relationships. This is how trust can be earned, even remotely.
There is one last important detail, nowhere above did I mention that the real-world identity of the sports betting wizard (e.g. Jane Picker of 411 Elm St. Springfield, IL) is ever revealed. The only requirement for a digital identity is a cryptographic key pair. The digital signatures prove that the published data came from the same identity controller and over time the controller gains a trustworthy reputation as a talented sports picker. By separating real-world identity from our digital identities in the ADE we can support both anti-privacy (i.e. financial) and pro-privacy (e.g. everything else) business online. This is perfectly aligned with the principles of user sovereignty and can restore a reasonable expectation of privacy and control over our data that most people desire.

A single controller can have many digital identities — sometimes called a “persona” — that have different levels of real-world information linked to them. We already experience this every day. You may comment on an online message board using your real world name but you may also choose to use a pseudonym. There typically isn’t a real-world identity requirement. Facebook and Twitter are different, they require you to link all of your posts to your real-world identity for business reasons. In the ADE, every person is a controller of many identities. You may even have multiple identities linked to your real-world identity that you use for different interactions to limit how much you can be correlated across different services. You may also have multiple identities that are specifically not linked to your real-world identity that you use for participating in commerce, healthcare, public discourse online and in any other privacy sensitive settings. As we will see later on, even if a digital identity is linked with your real-world identity the ADE enables fully privacy preserving interactions through the use of a special kind of cryptographic proof call a zero-knowledge proof.
In the ADE, the infrastructure needed for a controller to establish and maintain control over a digital identity must accomplish three things: proof-of-existence, linking, and publishing of cryptographic keys. The current non-scalable method for this is to use a blockchain — such as Bitcoin — to record what is called a decentralized identifier (DID) string that links to a DID document. The blockchain provides an immutable record proving the existence of the identity and when it was established. The DID string links to a DID document very much like how a universal resource locator (URL) links to a web site. The DID document itself is published somewhere public on the Internet and contains the cryptographic keys for the identity. All of this allows for authentic data to contain DID strings linking to public DID documents for the issuer identity and the recipient identity so that the digital signature and the data can be independently verified.
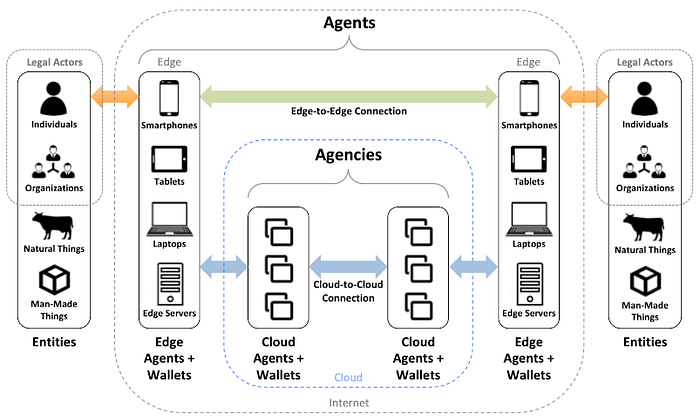
The first iteration of this infrastructure was slow, did not scale, was overly simplistic in some ways and wildly over-complicated in other ways and therefore prevented the ADE from being possible. It was built on the assumption that all identities and authentic data formats had to be recorded as transactions on a blockchain. Blockchains are notoriously slow making it impossible for this first design to improve even simple real-world problems. However, blockchains are also the most secure way to store data that is immutable and resistant to being changed. The current scalable solution for ADE pushes the blockchain to the edges and out of the critical path. There are several emerging examples — such as Microsoft’s ION — that use the Bitcoin blockchain for recording DID strings and DID documents in what is called a side tree. Side tree protocols enable high speed, scalable data updates and almost entirely eliminate the scalability problems of blockchains while preserving their extreme level of security. Getting the blockchain out of the critical path means the ADE is now possible.
Issuance
The next part of the authentic data economy is the infrastructure for supporting the creation and distribution of authentic data. Picking winning football teams and horses is subjective but anybody good at it can use their digital identity to publish their predictions and gain a positive reputation. Where this gets more interesting is when the data that is published is data that comes from companies or institutions with a trusted position in society. Since authentic data comes with proof of where it came from and proof that it hasn’t been modified any recipient of the data can trust it, regardless of how they received it.
A publisher of authentic data is called an issuer. Issuing authentic data includes identifying the issuer and recipient by including their DID strings and then digitally signing and maybe encrypting it to the recipient. Issuers have their own digital identities and the data they issue can be trusted at the same level as we trust the issuer person or organization. Issuers with a trusted role in the real-world are called trust anchors and they represent how human-scale trust gets transformed through the use of cryptography into digital trust. Some examples of trust anchors are corporations, governmental agencies, social and educational institutions, and any other person or organization that has a recognized role in society. The ADE does not do anything to improve real-world trust, it merely creates the means by which that trust is digitized and transmitted over the Internet.
The infrastructure needed for authentic data issuance is some software called an issuer service. Authentic data is typically issued to a person or organization called the holder and they use a piece of software called a wallet. The issuer service can issue two different types of authentic data: revocable and non-revocable data. Revocable data also requires some additional data called a non-revocation proof that the issuer makes publicly available that has a role in doing transactions using authentic data that we will investigate later. Non-revocable data is plain authentic data and has limited utility in the ADE. Typically non-revocable data is only created as part of sensing networks such as weather data where the primary concern is that the data has not changed since its creation.
Revocable authentic data is critical to the ADE because it allows for issued authentic data to be rendered untrustworthy by the issuer, independent of the actions of the holder of the data. A good example use case that relies on revocation is in credentialing and licensing. Typically credentials (e.g. board certified physician) and licenses (e.g. commercial pilots license) are things that must be maintained through continuing education, evaluation, and good behavior. If a physician or a pilot does something that calls into question their ability to perform those duties their credential/license is taken from them; it is revoked. The digital forms of these credentials and licenses must also be revocable for the trust to be digitized.
The first iteration of the infrastructure for creating revocable credentials was not useful because it is severely limited in real-world applications. The scalability problem in the old method comes from the fact that the non-revocation proofs that prove that a piece of authentic data has not been revoked grows with the number of pieces of authentic data. Up until recently this remained the primary limitation holding back the adoption of the ADE. But my friend Mike Lodder invented a new approach that allows for the creation of non-revocation proofs that are always the same size — 300 bytes — in constant time no matter how many pieces of revocable authentic data are issued. Not only that, but the cryptography used is simpler and much faster than the first generation of this technology. I cannot stress enough how important this is to making the ADE work. Trust is something that can be earned and it is something that can be lost. Digital trust systems must support revocation and until Mike’s innovation they could not do that at the global scale of billions and billions of pieces of authentic data. We now have the last piece in place to make the global authentic data economy real.
Verification
The verification of authentic data is the last piece of the ADE puzzle and it is the trickiest. The verifiers are where authentic data is received and the trust it transmits is converted from digital trust back into real-world trust to complete some transaction. All of the security created by the cryptography and digital identity management infrastructure is all there to support the verification of authentic data.
Up until now all of the promoters and companies working in the ADE industry have missed a few key pieces in verification. Typically they describe the ADE as having just three main participants: issuer, holder, and verifier. This is incomplete. There is a fourth role called the aggregator that is necessary for the ADE to work in the real world. The ADE will have many issuers and many verifiers that will need to know about the issuers’ identity and non-revocation proofs. This sets up what is called the many-to-many problem in computer science. The solution for the many-to-many problem is to have a single participant that all of the issuers talk to that also talks to all of the verifiers. That participant is the aggregator. The aggregator is responsible for gathering all of the issuer identity information and non-revocation proofs — aggregating it — and then transmitting the data to verifiers so that they have all of the data needed to verify authentic data from any issuer.
It also turns out that to make the ADE work, there needs to be a common set of standards for certain kinds of authentic data such as a digital drivers’ license, digital passport, or a digital COVID immunity record. We call these verifiable credentials. We also require a set of standards that define what constitutes a valid check of verifiable credentials. To put it more directly, if a holder of a digital drivers’ license wishes to prove that they are 21 years of age or older, not only do we need a standard for what data is in a digital drivers’ license but we also need a standard for what constitutes a valid age verification check. Sometimes those standards may change and those changes need to be sent to all verifiers. In the ADE, the aggregator comes to the rescue again. Along with ensuring that the verifiers have all of the issuer identities and non-revocation proofs, they also ensure that verifiers also have the definitions of verifiable credentials and valid check requirements.
Aggregators operate in a push model whereby they push the updated data to verifiers. This, along with transaction micro-ledgers (described later), enables doing verifiable credential checks both online and offline. Without the aggregator role assisting the verifiers, the whole ADE breaks down and fails to meet the requirements of real-world transactions.
When an issuer issues authentic data the way non-revocation proofs are generated is by including a unique identifier — a very large random number — in each piece of authentic data and then storing that unique identifier in a non-revocation proof. Mike Lodder’s key breakthrough is a technique for combining any number of these unique identifiers into a cryptographic accumulator that stays the same size no matter how many unique identifiers are added to it. Issuers will typically pre-generate tens of millions of unique identifiers and calculate and publish the non-revocation proof long before they are ever used in a piece of authentic data. The aggregators will then transmit the tiny 48 byte accumulator value to all of the verifiers so that they may confirm — both online and offline — that a piece of authentic data has not been revoked.
This is modeled after the CA systems non-revocation proof system in use today. When your browser connects to a web server, the web server not only sends the X.509 certificate for the server, but it also sends along what is called an Online Certificate Status Protocol (OCSP) response. The response is authentic data sent to the web server by the CA that issued the X.509 certificate that proves the certificate has not been revoked since the OCSP response was last updated. Typically the OCSP response is updated every day or week depending on the level of security required.
As mentioned above, the other piece needed to support offline verification and checks is what we call a transaction micro-ledger. A transaction micro-ledger records all messages sent between the holder of a piece of authentic data and a verifier that they are sending proofs to. Each message between them is stored in a hash-linked data structure and digitally signed by both the issuer and the verifier. Inside each message is a pseudonymous identifier for the holder and the verifier so that neither has to disclose their true identity to the other but if there is ever a regulatory action or a law enforcement investigation, one or both parties can provide the micro-ledger and the pseudonymous identifiers can be taken back to the issuers and translated back into the real-world identity of the holder and/or the verifier. The micro-ledger serves as an cryptographically secure record of the interaction so that any offline transactions can later be processed and external systems can be securely updated.
Privacy
There’s a great quote from Mitchel Baker (of Mozilla fame) I mention in my other article on the principles of user sovereignty:
Where is the open source, standards-based platform for universally accessible, decentralized, customized identity on the web? Today there isn’t one… Where is the open source, standards-based engine for universally accessible, decentralized, customized, user-controlled management of personal information I create about myself? Today there isn’t one.
The infrastructure for creating the authentic data economy is how we will make real the vision she lays out. However, the end result is so much more than just identity. It’s really about creating, transmitting, and consuming data in a secure and verifiable way; it is about a secure data supply chain. This is how we will achieve user sovereignty where each of us truly owns our data whether we created it or it was given to us (e.g. credit report). Third party data given to us as authentic data retains its value because of the guarantees and provenance protecting it.
The most incredible consequence of building the ADE is that we will all be able to conduct business both online and in the real-world while maintaining full control of our data and without forfeiting our privacy. But before I fully explain how that will happen I have a little more theory to throw at you. In the real world there are two classes of systems that rely on our personal information. The first class, class 1 systems, fall under regulations and laws that require the disclosure of personal information. Class 1 systems are mostly in banking and finance where regulations require that the source and destination of funds and the identities of the participants be disclosed for transparency reasons. The second class, class 2 systems, fall under regulations and laws that require personal information be kept private and any sharing be done so only with the consent of the person the information is about. My guess is that roughly 80% of all systems in the world are class 2 systems and the remaining 20% are class 1. There are some, such as fintech applications, that have some of both.
The ADE is naturally designed to support both. Class 1 systems are the easiest and in fact the ADE does a tremendous job of reducing the amount of fraud in these systems. So many government and corporate systems rely on paper credentials that can be forged. All of that would be impossible if they required verifiable credentials for identification.
Class 2 systems were not easily supported digitally until Mike invented his new non-revocation proof technique. To build privacy preserving class 2 solutions using authentic data, holders have to construct proofs called zero-knowledge proofs (ZKPs). Zero-knowledge proofs are a special kind of proof that can prove things about some authentic data without disclosing the authentic data to the verifier. The classic example is using a ZKP to prove that a holder is 21 years of age or older without disclosing their exact age. To make this secure, the ZKPs created by the holder also have to include a piece of data called a witness that, when combined with the accumulator from the issuer, proves that the authentic data has not been revoked by the issuer. This is the cryptographic equivalent of a bouncer looking at the expiration date on a drivers’ license to make sure it is still valid while also checking the persons’ birth date to ensure that they are old enough to enter the club.
Mitchel’s vision of a ubiquitous system for all of us to own and manage our own data is finally within reach. It is now possible for all of us to collect and store all of our personal information as authentic data and then use it in ZKP based transactions to get things done while preserving our privacy. ZKPs in the ADE enabled selective disclosure and reduced precision that can be tuned to each use case. It is designed specifically to support the user sovereignty principle of absolute privacy by default with the user being in control of their data. In some situations regulations may require the disclosure of some data but as stated earlier, the vast majority of systems can now be entirely privacy preserving.
A great example of what is possible is executing fully regulation compliant commerce transactions where the merchant doesn’t collect the customer’s real-world identity, nor do they collect the customer’s mailing address, nor do they collect any payment information from the customer. The customer can provide the merchant with a ZKP that not only proves that their bank knows their real-world identity but also contains a large random number that could later be used by law enforcement to find out their real-world identity if needed. The customer can also provide the merchant with a cryptographic proof — called a consent receipt — that allows them to get a shipping label from a package shipper that the customer has an account with. It doesn’t reveal their mailing address and the shipper bills them directly for the shipping fee. Lastly the customer can give the merchant a consent receipt to collect payment for the item directly from their bank and/or credit card company. All of these pieces of data are authentic data and both the customer and merchant stores them in a micro-ledger recording the interaction. This transaction can happen online as an e-commerce transaction remotely or between mobile devices in person. This can also happen offline between mobile devices that do not have any internet connection. The completion and reconciliation of the transaction will happen the next time the customer and/or the merchant goes back online.
Conclusion
With each successive wave of computerization the new innovations built on the last. Each one taking more of human-scale processes and shrinking them down and putting them into computers and eventually online. The authentic data economy isn’t any different. It leverages data collection and networking and personal computing advances. It makes our data ours and authentic. It builds on all of the previous work done by countless engineers and inventors and dreamers. However, by being the last big problem it represents the final piece that brings together everything that came before it. The scope of the authentic data economy is literally everything in the human sphere. There is nothing that this won’t change. Trust will go everywhere and into everything. But most importantly, so will privacy.

